CI/CD Automation Optimization is the disciplined practice of reducing friction, failure rates, and operational drag in software delivery pipelines by improving build reliability, test execution, deployment orchestration, and feedback speed. In technical terms, it means treating the pipeline as production-grade software: measurable, observable, versioned, and continuously refactored to remove unnecessary work, unstable dependencies, and brittle steps.
This matters now because build systems have become one of the most expensive hidden liabilities in engineering organizations. As repositories grow, dependency graphs expand, test suites age, and teams ship more frequently, the pipeline starts accumulating build debt: slow jobs, flaky tests, duplicated steps, manual overrides, and configuration drift. The result is predictable. Engineers lose trust in CI, release cadence slips, and failures get normalized instead of fixed.
Who works on this long enough learns a hard truth: a pipeline that “usually works” is not reliable enough. In practice, the real cost shows up in context switching, retry culture, and delayed releases that force teams to choose between speed and confidence. The better approach is to design CI/CD as a system with explicit failure modes, tight feedback loops, and a maintenance budget that is smaller than the cost of ignoring it.
Key Points
- Build debt is not just slow execution time; it is the cumulative cost of flaky tests, brittle scripts, poor caching, and uncontrolled pipeline complexity.
- The fastest way to reduce pipeline failures is to measure failure patterns by stage, root cause, and ownership, then eliminate the highest-frequency breakpoints first.
- A healthy CI/CD system uses reproducible environments, deterministic dependency resolution, and observable execution traces so failures are diagnosable, not mysterious.
- Most “automation problems” are actually design problems: poorly scoped jobs, oversized pipelines, and weak contract boundaries between build, test, and deploy steps.
- Optimization should target developer trust as much as cycle time; a fast pipeline that engineers do not believe is worse than a slower one they can rely on.
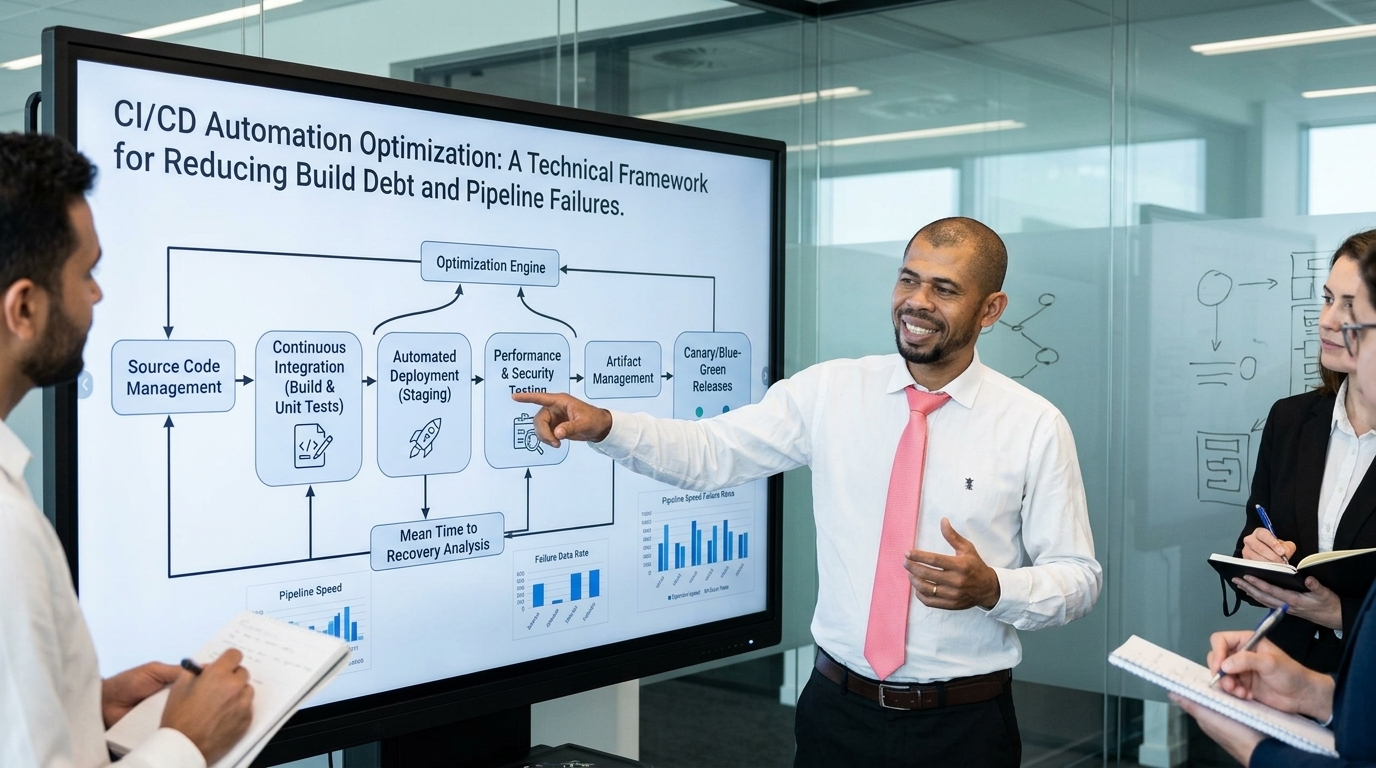
CI/CD Automation Optimization: A Technical Framework for Reducing Build Debt and Pipeline Failures
Define the System Before Tuning the Tooling
CI/CD automation is the orchestration of code validation, artifact creation, and environment promotion through automated pipelines. The technical goal is not to “run jobs faster” in isolation; it is to minimize variance in delivery outcomes. That means defining clear boundaries for build, test, security scanning, packaging, and deployment, then aligning each stage with a measurable reliability target.
When teams jump straight to tool changes, they usually miss the real constraint. A pipeline often fails because it tries to do too much in one execution path: linting, unit tests, integration tests, container builds, policy checks, and deploys are all chained together without enough isolation. That design creates coupled failure domains. One unstable step poisons the entire release process.
The formal way to think about this is as a production workflow with service-level objectives: latency for feedback, availability for runners, and error budget for failures. In plain language, if developers cannot predict how long a pipeline takes or whether a rerun will behave differently, the system is already underperforming.
Build Debt is Accumulated Operational Complexity
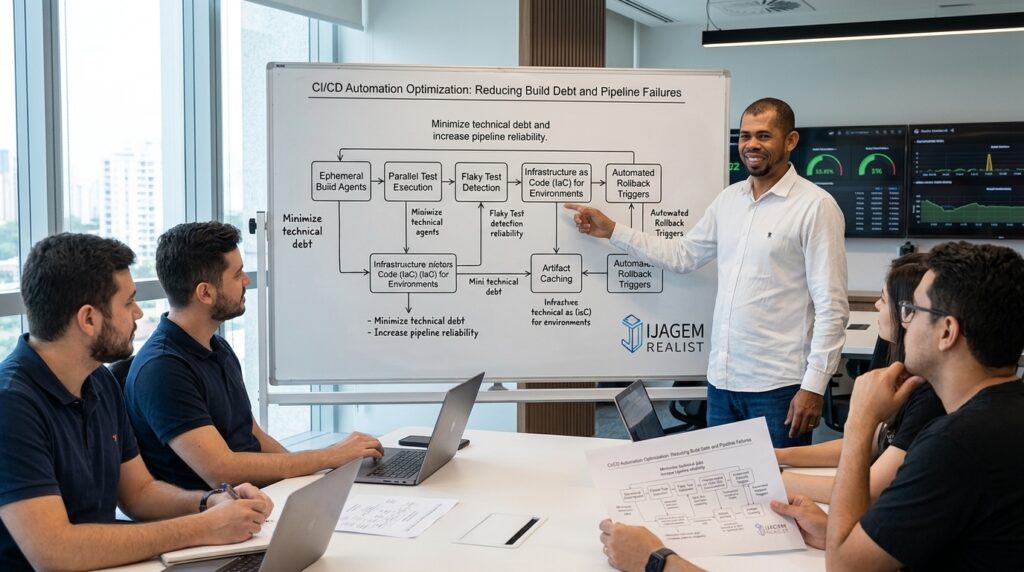
Build debt is the technical debt embedded in the delivery pipeline itself. It includes slow Docker image builds, outdated cache keys, dependency pinning gaps, nondeterministic test behavior, fragile scripts, and manual interventions that bypass automation. Unlike feature debt, build debt directly taxes every commit, so its cost scales with team activity.
Vi casos em que a organização acreditava que a causa principal era “testes lentos”, mas the real issue was a chain of small inefficiencies: an overbroad monorepo job, redundant package installation, and no artifact reuse between stages. Individually, each looked harmless. Together, they turned a five-minute validation into a twenty-minute bottleneck that engineers learned to ignore.
This is why reducing build debt requires systems thinking. You are not tuning a single command; you are reducing the number of moving parts that can fail, drift, or consume unnecessary compute.
Pipeline Failures Are Symptoms, Not the Disease
Frequent failures usually fall into a limited set of categories: flaky tests, environment mismatch, dependency resolution errors, infrastructure saturation, credential expiry, and race conditions between parallel jobs. The mistake is treating all failures as equivalent. A transient cloud outage is not solved the same way as a nondeterministic integration test.
Teams that track failures by category gain leverage quickly. They can distinguish code defects from platform defects, then decide whether the right fix belongs in the application, the build image, or the orchestration layer. Without that taxonomy, the organization defaults to retries, and retries are expensive because they hide root causes while preserving broken behavior.
For a practical reference on secure and repeatable software delivery, the NIST Cybersecurity Framework and software assurance resources are useful when you want to connect pipeline reliability with supply-chain discipline.
Designing Pipelines for Determinism, Isolation, and Fast Feedback
Determinism Starts with Reproducible Environments
A deterministic pipeline produces the same result given the same inputs. That sounds obvious until you inspect how many delivery systems depend on mutable base images, floating dependency ranges, unpinned package managers, or environment variables that differ between runners. Reproducibility is the first defense against false failures because it removes the guesswork from diagnosis.
The most effective pattern is to standardize build environments using locked container images or hermetic build tools. Cache aggressively, but never at the expense of correctness. If a cache can return stale or incompatible artifacts, it becomes a source of nondeterminism. The right mental model is “cache as an optimization layer,” not “cache as truth.”
Stage Isolation Prevents Failure Cascades
Strong pipelines separate concerns. Build steps should validate compilation and packaging. Test steps should assert behavior. Security scans should examine artifacts and dependencies. Deployment should promote known-good outputs. When these responsibilities blur, one failing concern can block unrelated work and make the entire system harder to reason about.
This is why monolithic pipeline jobs age poorly. They are efficient to start and expensive to maintain. By splitting stages into independently observable units, teams gain selective retries, better parallelization, and more accurate ownership. The payoff is not just speed; it is reduced blast radius.
Feedback Speed is a Product Decision
Fast feedback matters because it changes engineering behavior. If a failed commit surfaces in two minutes, developers fix it while the context is still fresh. If it arrives forty minutes later, the issue has already multiplied into branch divergence, reopen churn, and release hesitation. Build latency is not a vanity metric. It shapes how teams make decisions.
One useful policy is to establish a “critical path first” pipeline: compile, lint, unit tests, and the smallest meaningful gate run before heavier suites. Integration and end-to-end checks still matter, but they should not delay a developer from discovering a syntax error or a broken contract. That sequencing keeps the expensive checks for the commits that deserve them.
Pipeline Design Choice Operational Effect Typical Failure Mode Prevented Locked build image Improves reproducibility Environment drift Selective stage separation Reduces blast radius Coupled failures Early critical-path checks Speeds up feedback Late discovery of basic defects Artifact reuse Reduces redundant work Duplicate compute cost
Diagnosing the Real Sources of Build Debt
Flaky Tests Deserve a Separate Treatment Path
Flaky tests are one of the most corrosive forms of build debt because they destroy confidence faster than they destroy time. A test that passes on rerun is not healthy; it is a defect in the feedback system. Teams should track flake rate, test ownership, and historical stability, then quarantine or repair unstable tests rather than letting them blend into the normal failure rate.
The hard part is cultural as much as technical. When flaky tests become common, engineers stop believing red builds. At that point, every failure needs triage, and triage becomes a bottleneck. The fix is to make flakiness visible and expensive, so it cannot hide inside routine delivery noise.
Dependency Chaos Creates Hidden Fragility
Modern pipelines fail when dependency resolution is left too loose. Transitive updates, incompatible package versions, and registry availability problems can break a build without any code change. This is why version pinning, lockfiles, artifact repositories, and dependency scanning are not administrative extras; they are structural controls.
Organizations that ship containerized workloads should pay close attention to image layering and base-image update cadence. A small upstream change in an image or package index can affect every service downstream. That kind of shared dependency amplifies risk, so the correct response is governance, not ad hoc patching.
Pipeline Archaeology Reveals Maintenance Hotspots
One of the most effective exercises is to inspect where the pipeline spends time and where it fails most often. Teams usually discover that a few jobs account for a disproportionate share of retries, and a few scripts are responsible for most of the long-tail maintenance work. That is where build debt tends to live.
The analysis should cover execution duration, rerun frequency, manual intervention rate, and the number of distinct owners touching each job. A pipeline step with no clear owner will drift. A step with too many owners will fragment. Both conditions make failures harder to fix and easier to ignore.
For broader software engineering context on delivery performance and team capability, the research literature on software delivery and DevOps outcomes remains useful, though the exact findings vary by organization and domain. There is divergence among specialists on how much tooling versus process drives performance, and that debate is valid because context matters.
Observability, Governance, and Failure Management in CI/CD
Logs Are Not Enough Without Traceability
Raw logs help only when they are structured enough to answer a question quickly. A mature pipeline records job metadata, commit SHA, environment identifiers, artifact hashes, and timestamps in a way that makes correlation easy. Without those anchors, debugging becomes a manual scavenger hunt across build logs, cloud consoles, and deployment histories.
Traceability also matters for compliance and rollback. If you cannot prove which artifact was built from which commit, then your deployment history is incomplete. That gap is not theoretical; it becomes painful the first time a release must be reverted under time pressure.
Ownership Models Determine Whether Issues Get Fixed
Tooling does not fix broken accountability. Pipelines that span application teams, platform engineering, security, and infrastructure need explicit ownership boundaries. Every stage should have a named owner, a clear escalation path, and a threshold for intervention. If everyone owns the pipeline, nobody does.
In larger organizations, platform engineering often becomes the multiplier. It provides templates, runner management, reusable actions, and policy enforcement while product teams own application-specific tests and deployment logic. That split works well when the interface between teams is well defined. It fails when the platform becomes a gatekeeper instead of an enabler.
Policy Controls Should Prevent Repeat Failures
Failure management improves when pipelines encode rules that prevent known bad states from reappearing. Examples include branch protection, required checks, signed artifacts, secret scanning, and promotion gates. These controls reduce human judgment at high-risk points, which is where many recurring incidents begin.
The right level of governance is not zero and not maximal. Too little control creates drift; too much control slows delivery and encourages bypasses. The best systems enforce a few high-value rules tightly and leave room for teams to move quickly inside safe boundaries.
Practical Optimization Patterns That Scale Across Teams
Use Caching, but Design for Invalidation
Caching is one of the most powerful accelerators in a delivery pipeline, but it becomes dangerous when invalidation is poorly understood. Build caches, dependency caches, and test artifact caches should all be keyed to the inputs that actually affect correctness. If the cache key is too broad, you lose speed. If it is too narrow, you risk stale results.
The best implementation records what the cache depends on and what happens when those inputs change. This is where many teams save time immediately: package installs stop repeating, container rebuilds shrink, and test fixtures no longer get regenerated for no reason.
Parallelize the Right Work
Parallel execution reduces wall-clock time only when the jobs are sufficiently independent. Blind parallelization can overload runners, increase contention, and make failures harder to interpret. The goal is to parallelize along stable boundaries: test shards, service-specific builds, and artifact generation steps that do not depend on each other.
A common mistake is to parallelize everything and then wonder why infrastructure costs rise. The right approach is to identify the critical path, then fan out only the work that truly benefits from concurrency. That delivers faster feedback without creating a noisy, expensive pipeline.
Measure What Engineers Feel
Traditional DevOps metrics matter, but the best optimization programs also track engineering experience. If a team says the pipeline is unreliable, the perceived reliability matters even when aggregate failure rates look acceptable. Developer trust declines when reruns are common, failures are opaque, or waiting time interrupts flow.
Useful metrics include median time to green, failure recurrence rate, percentage of failures attributable to known causes, and manual intervention count per release. These are more actionable than vanity throughput numbers because they tie directly to friction in the delivery process.
- Reduce job scope before increasing compute.
- Prefer deterministic inputs over reactive retries.
- Keep high-frequency failures visible and assigned.
- Measure reliability by stage, not just by pipeline run.
- Optimize for developer trust, not only for raw speed.
Operating CI/CD as a Product, Not a Side Effect
Adopt a Maintenance Budget for the Pipeline
A delivery pipeline needs scheduled care the same way production services do. If no time is reserved for refactoring job definitions, refreshing runners, pruning dead steps, and updating images, build debt grows quietly until it starts affecting release readiness. The discipline is to treat pipeline work as first-class engineering work, not cleanup.
That maintenance budget should be visible in planning. Teams that do this well allocate recurring capacity to platform reliability and pay down the oldest failure modes before they metastasize. The return on that investment is lower interrupt volume and fewer release surprises.
Standardize Without Making the System Rigid
Reusable pipeline templates, shared actions, and policy-as-code reduce duplication, but standardization should not erase the legitimate differences between services. A monolith, a microservice, and a data pipeline do not need identical checks. The winning pattern is a shared foundation with configurable extension points.
This balance matters because overstandardization creates shadow workflows. If a template is too rigid, teams circumvent it. If it is too loose, every service invents its own logic. Good CI/CD governance makes the right path the easiest path.
Expect Tradeoffs and Manage Them Explicitly
There is no universal optimum. A pipeline optimized for maximum speed may sacrifice test depth. A pipeline optimized for maximum assurance may slow developers enough to reduce adoption. The correct choice depends on release risk, system criticality, team size, and regulatory context.
That is the limit of any optimization playbook: it works well when the bottleneck is clear, but it can fail when the organization is solving the wrong problem. If the real issue is flaky infrastructure, more test parallelism will not save you. If the real issue is poor architectural boundaries, better caching will only buy time.
The best CI/CD systems are not the ones with the fewest failures on paper. They are the ones that surface problems early, make root causes obvious, and keep engineers confident enough to ship without ceremony.
Próximos Passos Para Implementação
The practical path starts with visibility. Instrument the pipeline by stage, classify failures by cause, and rank the top sources of delay and reruns. Once the real bottlenecks are visible, eliminate the most common failure mode before reaching for broader redesign. That sequence matters because teams often spend months on platform changes while the actual pain comes from one unstable test suite or one brittle dependency chain.
From there, harden reproducibility, isolate stages, and reserve maintenance capacity for the pipeline itself. A mature CI/CD program is not judged by how much automation it has; it is judged by how little uncertainty it leaves behind. For teams willing to treat delivery as a core product system, the payoff is lower build debt, fewer pipeline failures, and release processes that scale with the business instead of fighting it.
Frequently Asked Questions
What is Build Debt in CI/CD?
Build debt is the accumulation of inefficiencies and fragility inside delivery pipelines, such as flaky tests, slow jobs, poor caching, and unstable environment setup. It behaves like technical debt because it taxes every future build and release. The more frequently your team ships, the more expensive build debt becomes. Left untreated, it turns CI from a confidence system into a recurring source of delay.
How Do You Identify the Main Causes of Pipeline Failures?
Start by classifying failures into a few stable categories: test instability, dependency issues, environment drift, infrastructure saturation, and deployment errors. Then measure frequency, rerun rates, and time to resolution for each category. The goal is to find the handful of causes that create most of the disruption. Once those are visible, you can fix root causes instead of treating every red build as a separate mystery.
What is the Fastest Way to Improve CI Feedback Time?
The fastest gains usually come from shrinking the critical path and removing unnecessary work from the first validation stage. Run compilation, linting, and the smallest high-signal tests first, then move heavier suites later. Cache only deterministic inputs and avoid forcing every commit through expensive checks that do not add early value. This approach reduces waiting time without weakening the quality gate.
Are Flaky Tests Always a Code Problem?
No. Flaky tests can come from code, but they also arise from timing issues, shared state, network dependencies, unstable test data, and environment variance. Treating them as pure code defects misses half the problem. A reliable fix often requires better isolation, more deterministic fixtures, and tighter control over external dependencies. That is why flakiness should be managed as a pipeline reliability issue, not only a test issue.
When Does CI/CD Standardization Go Too Far?
Standardization goes too far when it forces unrelated services into identical workflows and teams start bypassing the template to move at all. That creates shadow processes and undermines governance. A strong standard should simplify the common case while still allowing service-specific checks where they are justified. The right balance reduces duplication without flattening important differences in risk or architecture.
Editorial Notice
This content was structured with the assistance of Artificial Intelligence and subjected to rigorous curation, fact-checking, and final review by Editor-in-Chief Nivailton Santos. TechTool Judge reaffirms its unyielding commitment to journalistic ethics, ensuring that editorial judgment and data validation remain entirely under human responsibility and final editorial oversight.



