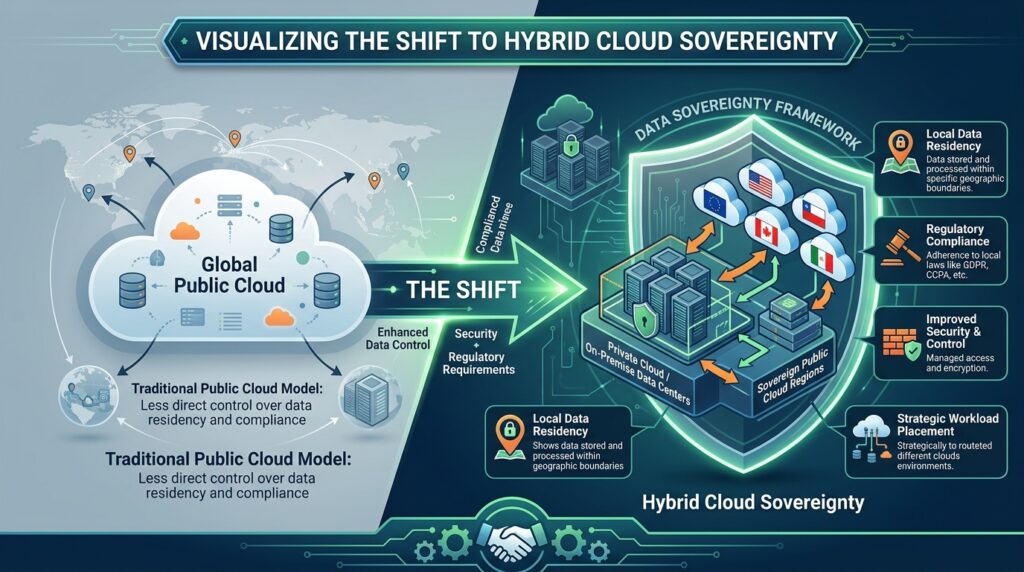
Hybrid Cloud Sovereignty is the operating model where an organization keeps control over where data lives, how it moves, who can access it, and which legal and technical controls apply across on-premises systems, private cloud, and public cloud. In the AI era, that definition expands beyond storage and access. It now includes lineage, model inputs, training data, inference logs, retention rules, and the ability to prove that sensitive information has not been altered, exposed, or governed by the wrong jurisdiction.
This shift matters because AI systems do not just consume data; they amplify its risks. A weak control at the ingestion layer can contaminate a model. A poorly governed cross-border transfer can trigger regulatory exposure. A missing integrity check can turn a trusted dataset into an unreliable one. That is why executives, security teams, and data leaders are moving from “cloud-first” thinking to sovereignty-by-design. The goal is not to reject the cloud. The goal is to use the cloud without surrendering control.
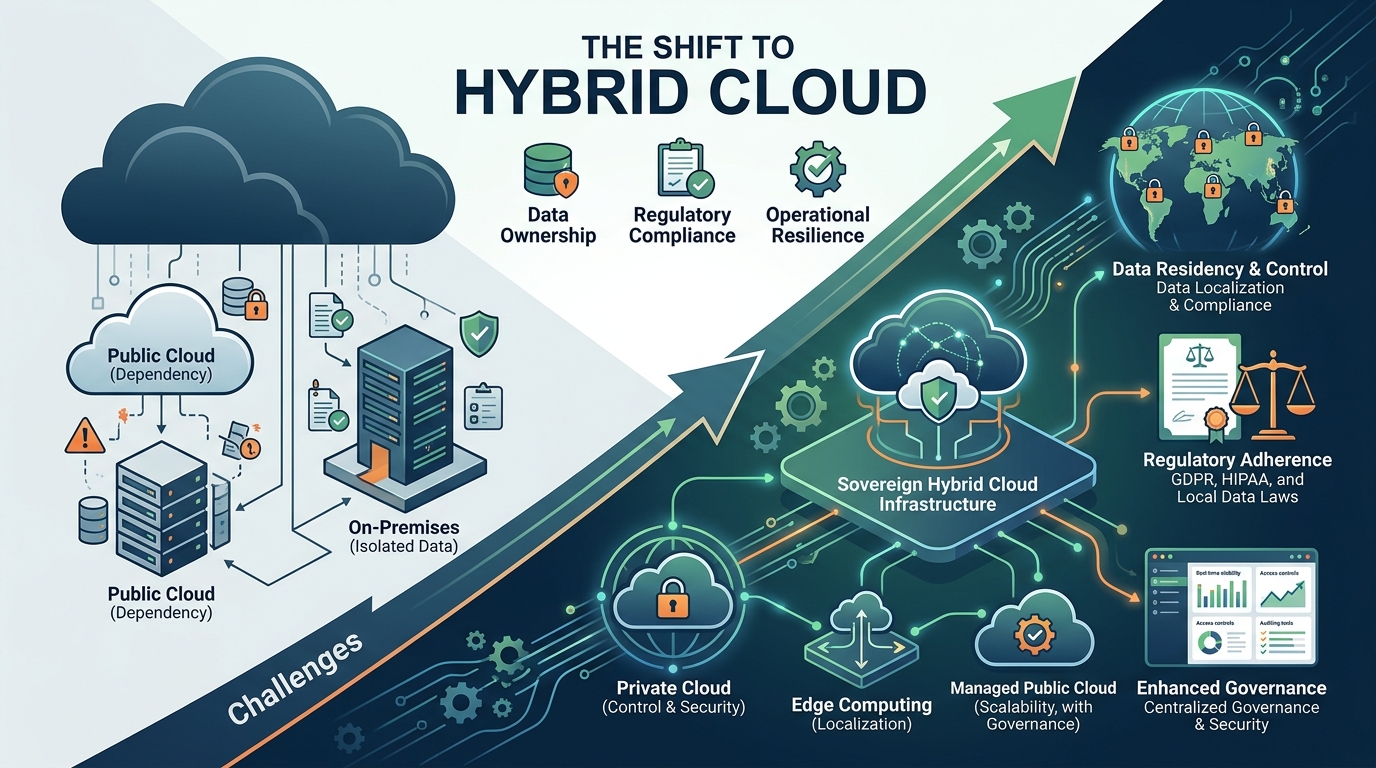
In practice, the organizations that win here are the ones that treat sovereignty as an architecture decision, not a compliance afterthought. They design for data residency, encryption boundary control, policy enforcement, auditability, and workload placement from day one. They also accept a hard truth: no single cloud model solves everything. The strongest posture often comes from a hybrid design that matches sensitive workloads to the right environment instead of forcing every asset into one provider’s stack.
Key Points
- Hybrid cloud sovereignty is about retaining enforceable control over data, workloads, keys, and governance across multiple environments, not simply choosing a private cloud.
- Data integrity has become a first-class AI risk because corrupted, unverified, or overexposed datasets can degrade model quality and create legal exposure at the same time.
- The best sovereignty strategy combines workload segmentation, encryption governance, identity control, lineage tracking, and audit-ready policy enforcement.
- Cloud regions and vendor contracts matter, but they are not enough; operational sovereignty depends on architecture, not paperwork alone.
- Hybrid designs often outperform single-cloud strategies when organizations must balance latency, resilience, regulatory scope, and sensitive-data handling.
The Shift to Hybrid Cloud Sovereignty: Protecting Data Integrity in the AI Era
What Sovereignty Means in Technical Terms
Technically, cloud sovereignty is the ability to define and enforce where data is processed, stored, encrypted, accessed, and audited, while keeping those controls aligned with legal and organizational requirements. In a hybrid environment, that means a workload may run in a public cloud such as AWS, Microsoft Azure, or Google Cloud, while the most sensitive data, keys, or policy engines remain in a private cloud or on-premises stack. The boundary is not the provider; it is the control plane.
That distinction matters because many teams confuse “regional hosting” with sovereignty. A data center in a country does not guarantee sovereign control if the provider can still influence access paths, metadata, or support operations under foreign jurisdiction. True sovereignty also depends on who manages the encryption keys, whether identity federation is under your control, and whether logs and lineage records can be preserved for forensic review without provider dependency.
Why Hybrid is Replacing Pure Public Cloud Thinking
The market has matured past the idea that public cloud is the default answer for every workload. Regulators are scrutinizing cross-border data flows, boards are asking harder questions about operational resilience, and AI pipelines are forcing companies to classify data with far more precision than before. A hybrid architecture gives leaders a practical way to place workloads according to sensitivity, performance, and jurisdiction instead of forcing a binary choice.
Who works in this field knows the pattern well: high-value data tends to concentrate, then sprawl. An AI pilot starts with a clean dataset in one cloud account, then grows into shadow exports, duplicated feature stores, and ad hoc notebook access. Hybrid sovereignty interrupts that drift. It gives architects a framework to contain sensitive data domains, keep development velocity, and avoid the all-too-common situation where convenience quietly outruns governance.
Data Integrity is the Real Prize
Data integrity means the data remains accurate, complete, consistent, and unaltered except through authorized processes. In AI systems, integrity is not a back-office concern. It affects training quality, retrieval accuracy, and model behavior. If a dataset is poisoned, duplicated, truncated, or silently transformed, the model may still produce confident answers while becoming less trustworthy.
That is why sovereignty and integrity now sit on the same risk map. A sovereign design that cannot prove integrity is incomplete. Likewise, integrity controls without jurisdictional and access governance are fragile. The organizations taking this seriously are building end-to-end controls: checksums, immutable logs, signed datasets, role-based and attribute-based access control, and policy gates that stop data movement unless it satisfies residency and classification rules.
Why AI Changed the Stakes for Governance and Control
AI Systems Expand the Attack Surface
AI does not just use data; it transforms data into prompts, embeddings, vector indexes, and model outputs. Each transformation creates a new chance for leakage or corruption. A retrieval-augmented generation pipeline, for example, may expose internal policy documents to users if the vector database is misconfigured. A model fine-tuned on unvetted content may inherit bias or hallucination patterns that are hard to trace later.
This is why many security teams now treat AI pipelines as production-grade data systems, not experimental sandboxes. The controls must cover ingestion, storage, training, inference, logging, and export. Without that discipline, the organization gets the worst of both worlds: cloud convenience and fragmented accountability. The Hybrid Cloud Sovereignty discussion becomes urgent the moment AI starts influencing customer decisions, financial operations, or regulated workflows.
Lineage and Provenance Have Become Board-level Issues
Data lineage shows where data came from, how it changed, and where it went. Provenance identifies origin, ownership, and transformation history. In the AI era, these are no longer niche metadata fields. They are evidence. If a regulator, customer, or internal audit team asks whether a model relied on approved data sources, the answer must be traceable, not anecdotal.
Organizations that invest in lineage tools, data catalogs, and policy enforcement platforms gain a practical advantage. They can isolate problematic sources faster, rebuild trust after incidents, and demonstrate compliance with less manual effort. This is one reason frameworks from NIST’s AI Risk Management Framework are being adopted so widely: they force teams to connect technical controls with governance outcomes rather than treating them as separate disciplines.
Jurisdiction Now Shapes Architecture Decisions
The legal environment matters because different regions impose different expectations for privacy, disclosure, retention, and access. The European Union’s GDPR has long shaped data handling requirements, and the expansion of AI governance rules is making those boundaries more consequential. In parallel, cloud customers are reassessing whether their provider relationships create hidden dependency risks when governments issue lawful access requests or when support processes touch sensitive metadata.
That does not mean hybrid cloud is a legal shield. It is not. It does mean architecture can reduce exposure by localizing sensitive processing, controlling where keys are held, and limiting where regulated data can be replicated. For many enterprises, that is the difference between a manageable compliance posture and a brittle one.
Control Area What It Protects Why It Matters for AI Data residency Where data is stored and processed Limits jurisdictional exposure and simplifies compliance scoping Key management Encryption control and decryption authority Prevents provider-side access from becoming uncontrolled access Lineage tracking Source and transformation history Supports model audits, debugging, and evidence-based governance Policy enforcement Who can move, read, or export data Stops sensitive data from leaking into training or inference flows Immutable logging Tamper-evident activity records Enables forensic review and trust restoration after incidents
Architecture Patterns That Actually Work
Segment Workloads by Sensitivity, Not by Politics
The most effective hybrid designs classify workloads by business risk and data sensitivity. Customer-facing analytics may live in a public cloud region, while regulated records, encryption keys, and model training on sensitive data stay in a private environment. This is not about ideological preference. It is about choosing the right containment model for the right asset.
In real deployments, the mistake is usually over-consolidation. Teams assume one platform simplifies governance, but the opposite often happens when every dataset, notebook, and service account gets pooled into a single environment. Segmentation creates smaller blast radii. It also makes audits more defensible because each control domain has a clear purpose and owner.
Keep Encryption Sovereignty Separate from Cloud Hosting
Encryption at rest is not enough if the cloud provider controls the keys or the key lifecycle. Mature teams use customer-managed keys or external key management systems, with policy separation between the host platform and the decryption authority. That way, the provider can run the infrastructure without gaining unilateral access to the content.
For highly sensitive deployments, hardware security modules and confidential computing can strengthen the model further. Confidential computing reduces exposure during processing by isolating workloads inside trusted execution environments. It is not a cure-all, and it does not eliminate application-level flaws, but it raises the bar for memory scraping, privileged access abuse, and some classes of insider threat.
Design for Observability, Not Just Compliance
A common failure mode is building controls that satisfy a policy document but do little for operations. The better approach is to make compliance data useful in real time. Security teams need to see who accessed a dataset, where it moved, whether it crossed a policy boundary, and whether the hash of the source material still matches the approved version.
Tools such as data catalogs, zero trust access policies, SIEM integrations, and DLP controls should not live as separate islands. They need to share context. That is how a governance team catches a suspicious export before it becomes a breach report. It is also how data engineers avoid accidental violations when they are moving fast and the process is not obvious.
How to Protect Data Integrity Without Slowing AI Delivery
Build Control Points Into the Pipeline
The fastest way to protect data integrity is to place checks where the data already moves. Validate ingestion with schema enforcement, verify source signatures, quarantine unknown inputs, and require approval for sensitive joins. Then preserve immutable records of each transformation so the lineage stays intact from raw source to model output.
This is where many organizations overcomplicate the solution. They try to bolt governance on after the pipeline is built, and adoption collapses under friction. A better model is to embed policy into the workflow itself. If a developer needs a special exception to move data, the system should route that request through an approval step automatically, not rely on informal messaging and hope.
Use AI-specific Controls for Prompts, Embeddings, and Training Sets
AI pipelines create data objects that traditional governance tools often miss. Prompts may contain personal or proprietary information. Embeddings can leak semantic traces of sensitive text. Training sets can include stale, duplicated, or adversarial content. Each of those objects needs classification and retention rules just like the underlying database tables do.
The practical response is to extend governance to the full AI lifecycle: redact before logging, restrict who can query vector stores, version datasets before model training, and document which sources are allowed for each use case. That discipline pays off when an audit or incident forces the team to prove exactly what the model saw and when it saw it.
Accept the Limits of Automation
Automation helps, but it does not replace judgment. There is still a place for human review on ambiguous classification, cross-border exceptions, and high-impact model deployments. Some specialists disagree on how much can be automated safely in regulated environments, and that disagreement is healthy. It reflects the fact that data sensitivity is not always static; context changes the risk.
Hybrid Cloud Sovereignty works best when the machine handles routine enforcement and people handle policy exceptions. That balance keeps delivery moving while preventing the kind of silent exception creep that usually leads to serious governance failures. Automation should reduce toil, not erase accountability.
Decision Criteria for Leaders: When Hybrid Sovereignty is the Right Move
Use This Model When Regulation, Latency, and AI Risk Collide
Hybrid sovereignty is not mandatory for every organization. A startup with low-sensitivity workloads and limited regulatory exposure may not need the same level of control as a bank, hospital, defense contractor, or multinational manufacturer. The tipping point appears when three pressures overlap: regulated data, AI adoption, and distributed operations across multiple jurisdictions.
That is the profile where a single-cloud or fully centralized strategy becomes fragile. If your AI roadmap depends on sensitive data, regional processing constraints, or strict auditability, hybrid is not a compromise. It is the architecture that gives you room to grow without losing control.
Watch the Trade-offs Before You Commit
Hybrid cloud introduces cost, skills, and integration overhead. It can increase the burden on platform teams, complicate observability, and create governance sprawl if ownership is unclear. That is the honest downside, and it should not be minimized. A poorly run hybrid environment is more confusing than a simple cloud estate.
The key is to enter with a narrow purpose: protect the most sensitive data, preserve integrity, and define the sovereign boundary with precision. If the organization tries to hybridize everything at once, the program will bog down. If it starts with the highest-risk workloads and proves value there, adoption becomes much easier.
Measure Success with Concrete Indicators
Executives should not evaluate sovereignty by how many policies were written. They should measure whether the organization can answer specific questions quickly and reliably. Can it prove where regulated data is stored? Can it show who accessed the training set? Can it detect changes to source data before they reach a model? Can it revoke access without breaking core operations?
Those are the markers of a mature program. They are also the indicators that a hybrid model is doing its job. The strongest teams build dashboards around these questions and review them as part of operational governance, not just annual compliance cycles.
- Percentage of sensitive datasets mapped with verified lineage
- Time required to revoke privileged access across cloud environments
- Number of AI workloads with approved residency and retention policies
- Rate of failed policy checks at ingestion and export points
- Mean time to detect unauthorized data movement
Próximos Passos Para Implementação
The organizations that move first will not be the ones with the most complex slide decks. They will be the ones that define a sovereign boundary, assign ownership, and instrument the pipeline before the AI rollout accelerates. Start by classifying data, then map which workloads truly need public cloud elasticity, which require private control, and which should never cross that line. That sequence matters more than vendor selection.
From there, align encryption governance, identity management, lineage tracking, and audit logging into one operating model. Use frameworks such as the NIST Zero Trust Architecture guidance to harden access decisions, and pair them with policy rules for residency and AI lifecycle controls. If a vendor cannot support those requirements cleanly, that is not a small gap. It is a strategic signal.
The future belongs to teams that treat trust as an engineered property. In AI-driven environments, sovereignty is not about avoiding the cloud; it is about preserving control while exploiting scale. Get that balance right, and you protect data integrity without putting innovation in a cage.
FAQ
What is Hybrid Cloud Sovereignty in Practical Terms?
Hybrid cloud sovereignty is the ability to control where data is stored, processed, encrypted, and audited across private and public environments. In practice, it means deciding which workloads can live in the cloud, which keys stay under your control, and which datasets must remain in a specific jurisdiction. It is less about ownership of infrastructure and more about enforceable governance across the full lifecycle of data and AI workloads.
Why Does AI Make Data Integrity Harder to Protect?
AI systems create more transformation points than traditional applications: ingestion, labeling, embedding, training, inference, and logging. Each step can introduce corruption, duplication, or leakage if controls are weak. The problem is not only security; it is trust in the output. A model can appear accurate while being trained on incomplete or manipulated data, which makes integrity monitoring a core requirement.
Is Public Cloud Incompatible with Sovereignty?
No, public cloud is not incompatible with sovereignty. The issue is whether you can enforce the controls you need over residency, access, key management, and auditability. Many organizations use public cloud successfully for sovereign workloads, but they do so with stronger governance and clear boundaries. The provider is part of the architecture, not the owner of the control model.
What Controls Matter Most for Proving Data Integrity?
The most important controls are source validation, schema enforcement, cryptographic hashing, immutable logging, lineage tracking, and restricted access to transformation pipelines. For AI workloads, you also need versioning for training data and policy checks before anything reaches a model. These controls work together; no single control can prove integrity on its own.
When Does a Hybrid Model Become Too Complex?
Hybrid becomes too complex when ownership is unclear, policy engines are inconsistent, or every exception requires manual coordination. At that point, the organization is paying the cost of multiple environments without getting the governance benefit. Complexity is manageable when the sovereign boundary is narrow, well-documented, and tied to a few high-value risks rather than every workload in the company.
Editorial Notice
This content was structured with the assistance of Artificial Intelligence and subjected to rigorous curation, fact-checking, and final review by Editor-in-Chief Nivailton Santos. TechTool Judge reaffirms its unyielding commitment to journalistic ethics, ensuring that editorial judgment and data validation remain entirely under human responsibility and final editorial oversight.



