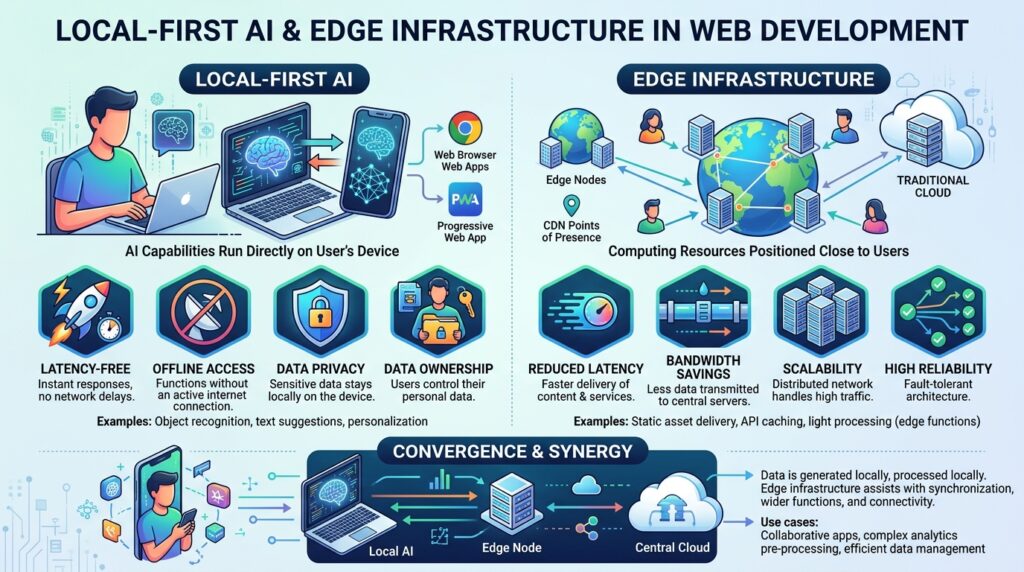
Local-First AI and Edge Infrastructure is a web architecture approach that keeps data processing, model execution, and user-state handling as close to the user as possible—on the device, in a nearby edge node, or in a hybrid path that avoids unnecessary round trips to centralized cloud systems. In practice, that means faster interactions, lower bandwidth dependence, and stronger privacy boundaries because sensitive data does not need to leave the browser or local network unless there is a clear reason to do so.
This matters now because modern web applications are being asked to do more at the same time: summarize documents, generate content, personalize experiences, search private data, and support real-time collaboration. Centralized AI stacks can handle those workloads, but they often do it at the cost of latency, recurring inference spend, and broader data exposure. A local-first design shifts the default assumption: compute locally first, use the edge when it adds value, and send data to the cloud only when the product truly needs it.
That shift is not ideological. It is a response to three concrete pressures: privacy regulation, user expectations around responsiveness, and the operational cost of moving large volumes of data through distant servers. Teams that understand Local-First AI and Edge Infrastructure are no longer asking whether the cloud is useful; they are asking which parts of the stack should stay near the user and which should remain centralized.
Key Points
- Local-first AI keeps sensitive computation on the client or in a trusted edge layer, which reduces exposure and improves perceived speed.
- Edge infrastructure is most valuable when latency, bandwidth, or regional data handling constraints make centralized inference inefficient.
- The strongest deployments use a hybrid design: device inference for fast, private tasks and cloud escalation for heavier workloads or coordination.
- Privacy gains are real, but they depend on rigorous model loading, storage isolation, and clear telemetry boundaries.
- Not every AI feature belongs on the device; larger models, regulatory logging, and organization-wide retrieval often still require server-side control.
Local-First AI and Edge Infrastructure in Web Development: What It Means and Why It is Different
Formal Definition: Compute Placement as a Product Decision
Technically, local-first AI refers to application designs where inference, state management, or both execute on the user’s device before any server dependency is involved. Edge infrastructure extends that idea one layer outward: it places services in geographically distributed nodes closer to the user, such as edge functions, regional caches, or runtime platforms like Cloudflare Workers, Vercel Edge Functions, and Fastly Compute. The goal is not just speed. It is a deliberate reduction of data movement, trust boundaries, and coordination overhead.
Put in plain language, local-first means the app should still work well when the network is slow, unstable, or unnecessary for a given task. If a model can draft text, classify content, or extract fields from a PDF on the device, there is no reason to round-trip that data through a distant API just to get it back a few hundred milliseconds later.
Why This Architecture is Gaining Ground
The web spent years optimizing for server authority. That made sense when browsers were thin clients and AI workloads were mostly remote. The current wave of application AI changed the economics. A small model on a phone, laptop, or browser runtime can now handle a surprising amount of work: embeddings, autocomplete, semantic search over local content, speech transcription, and lightweight summarization. The edge then acts as a bridge, not the center of gravity.
Who works in this field knows the pattern: users notice latency more than raw throughput. A 120 ms delay on a key interaction feels instant, while a 900 ms cloud call makes an interface feel uncertain. That is why edge caching, local model execution, and offline-friendly state sync are becoming core product concerns rather than niche architecture choices.
The Privacy and Performance Tradeoff is Not Symmetric
Privacy is usually the first selling point, but performance often becomes the deciding factor. Keeping data local reduces the amount of personally identifiable information that touches external systems. It also cuts network latency and lowers the risk of timeouts during peak load or poor connectivity. For regulated environments, that can simplify compliance reviews because less data leaves the device in the first place.
There is a limit, though. Local execution is not a universal win. Some tasks need large context windows, centralized audit logs, or cross-user coordination that is awkward to split across many devices. That is where a hybrid model is strongest: local for immediate interaction, edge for distribution and policy, cloud for heavyweight orchestration.
How Privacy Changes When Data Stays on Device or at the Edge
Attack Surface Shrinks, but It Does Not Disappear
Moving AI inference closer to the user reduces exposure, but it does not erase risk. A local model can still leak through logging, analytics, browser storage, clipboard access, or insecure prompt handling. The main security gain comes from minimizing what crosses the network, not from assuming the device is automatically safe.
That distinction matters in real deployments. I have seen teams celebrate “private AI” while sending raw prompts to telemetry vendors or storing embeddings in shared caches without strict tenant separation. The architecture was local-first in name only. The privacy posture improved only when developers aligned storage policy, model loading, and observability around the same trust model.
Compliance Teams Care About Data Flow, Not Marketing Language
Regulators and internal risk teams usually ask a few direct questions: Where does the data go? Who can access it? How long is it retained? Can it leave the region? Local-first designs help because they make those answers narrower and easier to document. This is one reason edge inference is attractive in healthcare, finance, education, and enterprise productivity software.
For reference, privacy and data-minimization principles are central to frameworks such as the National Institute of Standards and Technology guidance on risk management, and the GDPR overview remains a useful checkpoint for understanding data-processing obligations. In the U.S. browser and platform space, the Federal Trade Commission has also made clear that misleading privacy claims can create legal and reputational exposure.
Telemetry Must Be Designed, Not Added Later
One of the most common mistakes is treating observability as an afterthought. If the application is collecting prompts, embeddings, or user context for debugging, the privacy story changes immediately. A better pattern is differential logging: capture enough to diagnose system health without recording the content itself. Aggregate metrics, redacted traces, and local diagnostics are far safer defaults than raw payload storage.
That approach is not perfect. It can make debugging harder, and some incidents will require more context than a privacy-preserving pipeline prefers to expose. That tradeoff is real. The mature answer is to make sensitive logging opt-in, time-bound, and tightly access-controlled, not to pretend the tension does not exist.
Performance Engineering for Devices, Browsers, and Edge Runtimes
Latency is a Systems Problem, Not a Model Problem
Teams often focus only on model size when they think about speed. That misses the bigger picture. In user-facing AI, latency is the sum of startup cost, token generation speed, memory pressure, serialization, network hops, and UI rendering overhead. A smaller model can still feel slow if the app blocks on download, repeatedly reinitializes weights, or forces large context transfers between worker threads and the main UI.
Good local-first systems reduce that overhead in layers. They preload compact models, cache artifacts intelligently, and push noncritical tasks to a Web Worker or WASM runtime. On the edge side, they place routing logic, personalization, and lightweight inference near the user so that the application can answer fast without waiting on a faraway origin server.
What Runs Well on the Client, and What Does Not
Not all AI workloads belong in the browser. Small language models, intent classification, embeddings, voice activity detection, and short-form summarization often perform well on modern devices. Larger retrieval pipelines, cross-user recommendations, and long-context generation usually do not. The practical question is not whether a feature is “AI,” but whether the user experience benefits from local execution more than from centralized scale.
In production, developers often combine browser-side inference with edge routing and server-side fallback. That is the most durable pattern because it preserves responsiveness for the common case while leaving room for heavier computation when needed. Frameworks such as TensorFlow.js, ONNX Runtime Web, and WebAssembly-based inference engines matter here because they make browser execution less fragile than it was a few years ago.
A Useful Comparison of Deployment Layers
Layer Best Use Cases Main Strength Main Constraint Device / Browser Autofill, embeddings, summarization, offline tasks Lowest latency and strongest local privacy Limited memory, battery, and model size Edge Runtime Routing, personalization, lightweight inference, regional policy Close-to-user response and distributed control Restricted execution environment and cold starts Central Cloud Large model inference, training, audit logging, orchestration Scale and centralized governance Higher latency and broader data movement
Architecture Patterns That Actually Hold Up in Production
Hybrid Inference Beats Purity
The strongest systems rarely choose one layer exclusively. They use a hybrid architecture: the device handles immediate interactions, the edge handles distribution and policy, and the cloud handles expensive or coordination-heavy operations. That design avoids dogma. It gives the product team a fast baseline and preserves room for escalation when model quality, compliance, or scale requires it.
In practice, that means the browser may generate embeddings locally, the edge may route requests to a regional cache, and the cloud may only receive de-identified or aggregated state. The user sees a fast interface; the platform team sees a smaller blast radius. That combination is why the pattern keeps spreading.
State Sync is the Hard Part
If local-first AI were only about model placement, it would be straightforward. The real difficulty is state synchronization. Documents, preferences, embeddings, and conversation history need to stay consistent across devices without creating merge conflicts or leaking private content. This is where CRDTs, append-only logs, and selective sync strategies come in.
There is no universal winner. CRDTs work well for conflict-free collaboration but can become heavy for some data shapes. Server-authoritative sync is simpler in some enterprise settings but weakens the local-first promise. The right answer depends on how much offline tolerance the product needs and how much complexity the team is willing to manage.
Edge Platforms Shape the Developer Experience
The platform matters almost as much as the model. Cloudflare Workers, Vercel Edge Functions, and similar runtimes make it easier to place logic near the user, but they also impose constraints around execution time, memory, and native dependencies. That forces discipline. You learn quickly whether a piece of code belongs in the edge layer or should stay in the core application backend.
That discipline improves reliability. It also reduces hidden costs because edge functions are often used for small, frequent tasks that become expensive if they bounce through a centralized API. The best teams use the edge for what it does well: quick decisions, regional policy, and thin orchestration, not heavyweight business logic.
Implementation Decisions, Tooling, and the Cases Where It Fails
Choose the Smallest Useful Model
Model selection should begin with the task, not the benchmark chart. A smaller distilled model can outperform a larger one once you include warm-up time, memory pressure, and UI integration. If the product only needs classification, extraction, or short generation, the right move is often to avoid the larger model entirely. That is how teams keep the experience responsive on commodity hardware.
Common tooling choices include ONNX Runtime, TensorFlow Lite for edge-adjacent workflows, WebGPU for acceleration where available, and browser storage layers that respect encryption and partitioning. The WebGPU angle is important because it changes what can run locally at acceptable speed, especially for graphics-capable devices.
Plan for Failure Modes Early
Local-first does not mean local-only. Devices go offline, browsers suspend workers, and edge regions fail. Applications need fallback paths that degrade gracefully: cached responses, queued writes, reduced-functionality modes, and a clear path to cloud execution when the local route cannot complete the job. This is where many prototypes fail. They look elegant in a demo and collapse under ordinary network variability.
Who has shipped this knows the pattern: the first production bug is often not the model. It is state drift, stale cache invalidation, or a request that assumes synchronous internet access. A production-ready architecture treats those as first-class problems from the start.
When the Local-First Approach is the Wrong Choice
This model is not universal. It struggles when the product depends on large shared context, strict centralized auditing, or very high model capacity. It also loses some appeal on extremely low-power devices or in environments where browser support is inconsistent. If the workload is mostly server-side anyway, forcing local execution adds complexity without a proportional gain.
That is the main limit of the approach: it works best when the user experience benefits from immediacy and privacy more than it benefits from one centralized model brain. When the business problem is different, a classic cloud AI stack may still be the better fit.
Próximos Passos Para Implementação
The practical path is to start with one narrow feature that is latency-sensitive and privacy-sensitive at the same time. Good candidates include local autocomplete, on-device document summarization, embeddings for personal search, or a browser-side classifier that routes requests before they hit the backend. Measure the user-visible impact first: interaction time, offline resilience, and the amount of data no longer leaving the device.
From there, build the architecture in layers. Keep sensitive computation local by default, use the edge for distribution and policy, and reserve the cloud for tasks that truly require scale or centralized control. That is the most credible way to adopt Local-First AI and Edge Infrastructure without turning the system into a patchwork of accidental complexity. The winning teams will not treat privacy and performance as separate goals; they will use the same architecture to improve both.
The next step is validation, not ideology. Benchmark the local path against the cloud path, document where the approach breaks, and make those limits visible to product and security stakeholders before rollout. That is how this architecture earns trust in real web development work.
Perguntas Frequentes
What is the Main Difference Between Local-first AI and Edge AI?
Local-first AI runs inference or state handling on the user’s device before relying on a server. Edge AI places computation in nearby distributed nodes, which still reduces latency but does not keep data as close to the user as true device-side execution. In practice, many production systems combine both. The device handles immediate private tasks, while the edge supports routing, caching, and lightweight policy enforcement.
Which Workloads Are Best Suited for Browser-based Inference?
Tasks with modest compute needs and clear privacy value are the best fit: embeddings, intent classification, short summarization, autocomplete, and simple extraction. These workloads benefit from low latency and reduced data transfer. Browser-based inference works less well for very large models, long-context generation, or jobs that require heavy coordination across users or systems.
How Does Edge Infrastructure Improve Privacy If Data Still Leaves the Device?
Edge infrastructure improves privacy by limiting how far data travels and by reducing the number of centralized systems that touch it. Regional processing can keep data within a jurisdiction and avoid sending it through a distant core cloud account. That said, privacy depends on the full pipeline, including logs, caches, analytics, and retention rules. An edge layer alone does not create compliance.
What Are the Biggest Technical Risks in a Local-first Architecture?
The most common risks are state synchronization bugs, inconsistent performance across devices, and weak observability. Teams also underestimate the complexity of fallback paths when a local model fails or the user goes offline. Another frequent issue is assuming that local execution automatically means secure execution. It does not. Storage, telemetry, and permission handling still need careful design.
When Should a Team Avoid Local-first AI?
Teams should avoid it when the workload depends on very large models, centralized governance, or shared context that is hard to sync across devices. It is also a poor fit when device hardware is too limited or browser support is inconsistent across the target audience. In those cases, the extra engineering overhead may outweigh the benefits, and a cloud-centered design will be more reliable.
Editorial Notice
This content was structured with the assistance of Artificial Intelligence and subjected to rigorous curation, fact-checking, and final review by Editor-in-Chief Nivailton Santos. TechTool Judge reaffirms its unyielding commitment to journalistic ethics, ensuring that editorial judgment and data validation remain entirely under human responsibility and final editorial oversight.